簡單測試使用 WhisperDesktop 將語音轉成文字
WARNING
這篇是之前的測試紀錄,雖然 WhisperDesktop 還是能用,但開發者已許久未更新。 目前我已改用 Subtitle Edit 整合 Faster-Whisper,維護相對活躍且速度更快。 建議直接參考新文章:使用 Subtitle Edit 整合 Faster-Whisper 進行本地語音轉文字。
前段時間在看 ChatRTX 時,我看到 Whisper 這個名詞。經查詢後發現,OpenAI Whisper 是 OpenAI 於 2022 年 9 月發佈的語音轉錄和翻譯 AI 模型。如果想了解更多資訊可以參考 What is OpenAI Whisper? 這篇文章。
對於像我這樣的 AI 新手來說,要自己建立環境來運行這個模型有點困難。不過,有人開發出可以直接使用的離線版工具 WhisperDesktop。
下載與安裝
從 GitHub 儲存庫首頁右側邊欄的 "Releases" 區域點擊最新版本,目前版本是 Version 1.12。
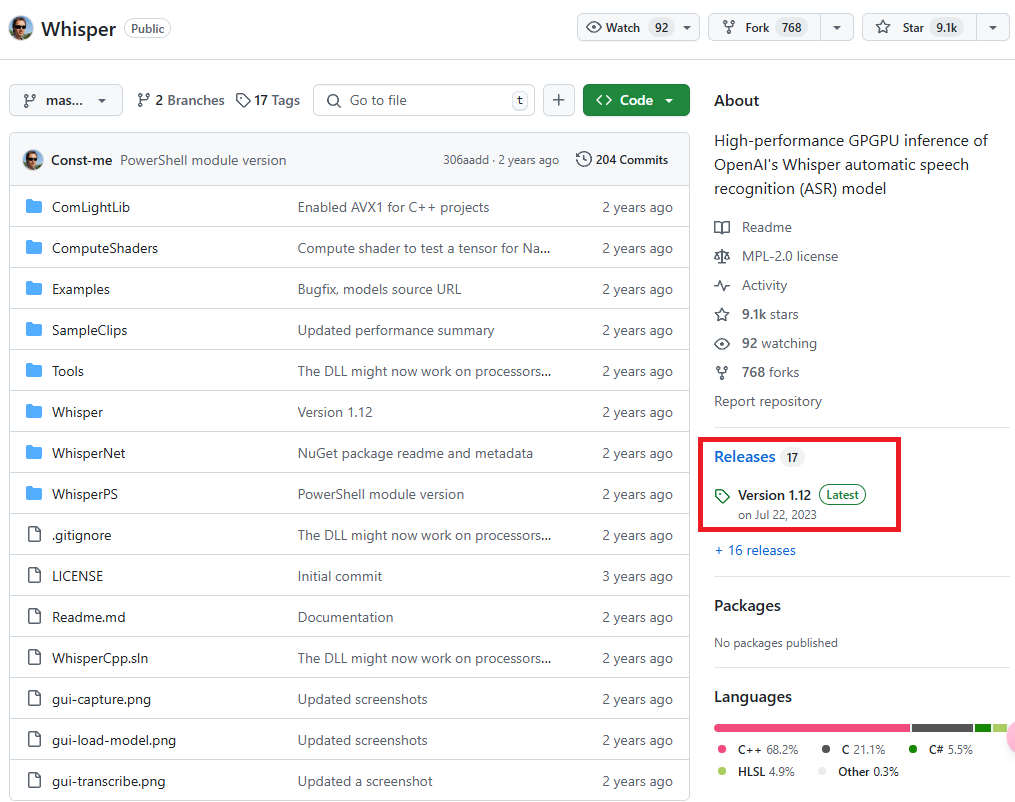
在 Release 頁面的 "Assets" 區域下方,點擊紅框標示的 WhisperDesktop.zip 進行下載。
解壓縮後,會看到以下三個檔案:
- WhisperDesktop.exe:實際執行檔案。
- Whisper.dll:函式庫檔案。
- lz4.txt:授權聲明。
下載模型
接著,需要從以下網站下載模型: Huggingface Whisper。
模型大小與規格
模型有不同大小可供選擇,帶有 .en 後綴的是英文專用版本,除此之外還有其他延伸模型。WhisperDesktop 作者推薦使用 ggml-medium.bin,因為這是他主要用來測試軟體的模型。
| 大小 | 參數數量 | 英文專用模型 | 多語言模型 | 需求 VRAM | 相對速度 |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
使用方法
執行 WhisperDesktop.exe。
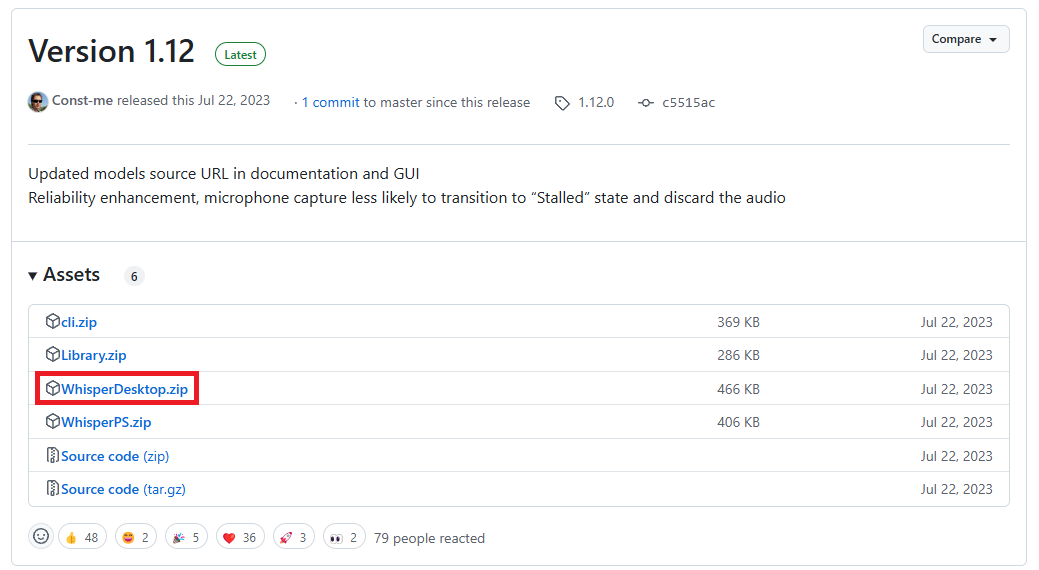
在 Model Path 欄位指定已下載的模型位置。
Model Implementation 選擇
GPU(其他選項我不知道用途,這邊就不說明了)。- 如果沒有正確偵測到顯示卡,可以點擊
advanced...進行細節設定。
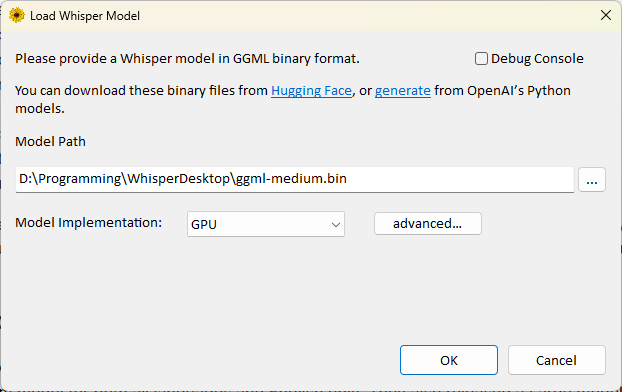
- 如果沒有正確偵測到顯示卡,可以點擊
點擊
ok。Language 選擇影片主要語言(中文只有 Chinese 選項,程式會自動判斷繁簡體,不過我也不知道他的判斷依據)。
若要翻譯成英文,請勾選 Translate,不過我測試音樂常翻失敗。
Transcribe File 選擇要轉成文字的音樂或影片檔案。
Output Format 可以選擇以下格式:
- None:不輸出檔案。
- Text file (.txt):純文字檔案。
- Text with timestamps:包含時間戳記的文字檔案。
- SubRip subtitles (.srt):常見的字幕格式,包含時間碼和文字。
- WebVTT subtitles (.vtt):網頁影片字幕格式。
指定輸出的檔案位置及檔名。
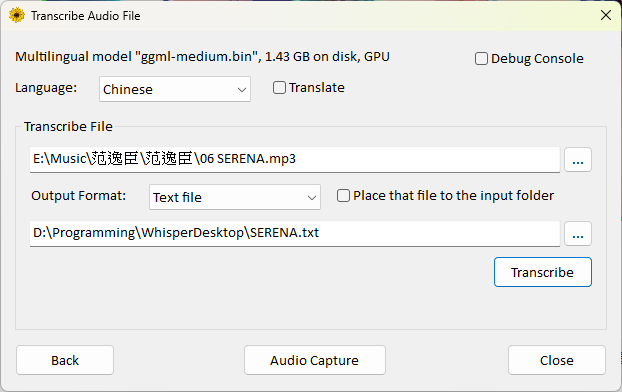
如果不想特別指定檔案輸出位置,可以勾選
Place that file to the input folder。- 這樣會將輸出檔案儲存在與輸入檔案相同的位置。
- 檔名會是原檔案名稱加上輸出格式對應的副檔名。
「Audio Capture」功能可以直接讀取麥克風輸入的語音,但我的電腦無法偵測到藍牙耳機,因此這部分暫不說明。
效能測試
使用 PNY RTX 4070 Ti Super 16GB Blower 顯示卡進行測試,轉換一個 5 分 16 秒的 mp3 檔案:
- 使用
ggml-large-v3.bin需要 22 分 01 秒,且不一定能成功轉換(實測時,檔案內容空白,可能需要使用其他版本的 large 模型才能正確轉出)。 - 使用
ggml-medium.bin僅需 11 秒即可完成。
使用 i7-12700H 內顯(無獨立顯示卡)進行測試,同樣是轉換 5 分 16 秒的 mp3 檔案:
- 使用
ggml-tiny.bin需要 41 秒。 - 使用
ggml-small.bin需要 4 分 19 秒。 - 使用
ggml-medium.bin需要 13 分 5 秒。
轉出來的文字正確率隨著模型大小增加而有明顯的提升。
結論
基於測試結果與速度考量,以下是我個人使用建議:
- 對於有獨立顯示卡的使用者:建議使用
ggml-medium.bin模型。 - 對於使用內顯或早期顯示卡的使用者:
- 日常使用:選擇
ggml-small.bin,這是可接受的最小模型,ggml-tiny.bin模型的準確率太差了。 - 重要內容轉錄:可以選擇
ggml-medium.bin並接受較長的處理時間,以獲得更高的準確度。
- 日常使用:選擇
異動歷程
- 2025-03-24 初版文件建立。
- 2026-01-31 新增推薦連結,引導至新版 Faster-Whisper 解決方案。